
Algorithmic buying and selling programs are sometimes mentioned by way of fashions, indicators, and execution logic. Nevertheless, earlier than any of those parts could be developed, researchers should first clear up a extra elementary drawback: dependable entry to monetary information.
In skilled analysis environments, information infrastructure isn’t a preliminary step. It’s a gating operate. If the info layer is inconsistent, each downstream mannequin inherits that instability. On this article, we give attention to the foundational layer of systematic buying and selling: monetary information infrastructure. We are going to discover how monetary information APIs like FMP allow automated information ingestion, how they match into quantitative analysis pipelines, and the way builders can use them to construct scalable analysis workflows utilizing Python.
Why Knowledge Infrastructure Issues in Algorithmic Buying and selling
Knowledge infrastructure determines whether or not a quantitative workflow can function reliably at scale. Earlier than fashions could be evaluated or indicators could be examined, researchers should make sure that monetary information is on the market in a structured, constant, and scalable type. With out this basis, even well-designed methods turn into troublesome to validate or reproduce.
Systematic Buying and selling Requires Dependable Knowledge Inputs
In systematic buying and selling, information points are hardly ever apparent at first. Small inconsistencies in inputs, equivalent to lacking values, misaligned timestamps, or formatting variations, propagate by means of the pipeline and warp function calculations, mannequin outputs, and backtest outcomes.
Knowledge Necessities in Quantitative Analysis
Quantitative workflows depend on a number of datasets that should combine seamlessly, together with value information, monetary statements, and event-driven data. As analysis expands throughout bigger universes and time intervals, managing these datasets turns into more and more advanced with out correct infrastructure.
Challenges with Guide Knowledge Assortment
Within the absence of automation, information assortment shortly turns into inefficient.
Guide workflows, equivalent to downloading spreadsheets or copying information from a number of sources, introduce a number of limitations. These strategies may match for small analyses, however don’t scale properly in a analysis atmosphere.
Some frequent points embody:
- Variations in information formatting throughout sources
- Problem in sustaining up to date datasets
- Restricted scalability when working with many securities
- Decreased reproducibility of outcomes
These challenges usually result in inconsistencies, making it troublesome to validate analysis outcomes over time.
Monetary Knowledge APIs because the Basis
Monetary information APIs allow a structured and automatic approach to retrieve datasets immediately right into a analysis atmosphere, changing guide workflows with programmatic entry.
In quantitative analysis pipelines, APIs primarily energy the info ingestion layer, the place datasets equivalent to costs, monetary statements, and estimates are retrieved and built-in immediately into the workflow. This permits repeatable information entry, simpler integration with Python-based pipelines, and extra scalable analysis processes.
What Is a Monetary Knowledge API
A monetary information API permits programmatic entry to monetary datasets, permitting information to be retrieved immediately inside code slightly than collected manually. It acts as an interface between a knowledge supplier and a analysis atmosphere, enabling information to be requested and consumed immediately inside code. In follow, builders additionally consider APIs primarily based on latency, charge limits, schema consistency, and the way reliably endpoints behave throughout large-scale requests.
In quantitative workflows, this implies a Python script or pocket book can retrieve datasets equivalent to historic costs, monetary statements, or analyst estimates with out counting on guide downloads.
How an API Works in Observe
The next diagram summarises how a typical API interplay flows from request to information utilization:
For instance, monetary information platforms expose endpoints for datasets equivalent to firm profiles, historic value information, and monetary statements, all of which comply with this request–response sample.
Guide vs Programmatic Knowledge Retrieval
The distinction between guide workflows and API-based workflows turns into clear when evaluating how information is collected
| Side | Guide Knowledge Retrieval | Programmatic Knowledge Retrieval |
|---|---|---|
| Effort | Excessive (repeated guide steps) | Low (automated by means of code) |
| Scalability | Restricted to small datasets | Scales throughout giant datasets |
| Consistency | Liable to formatting inconsistencies | Standardised and structured |
| Replace Course of | Requires guide updates | Robotically refreshable |
| Reproducibility | Tough to copy | Absolutely reproducible workflows |
For quantitative analysis, programmatic entry is considerably extra dependable as a result of it reduces human intervention and ensures consistency.
Authentication Utilizing API Keys
Most monetary information APIs require authentication by means of an API key, which is included with every request. It verifies consumer id and permits suppliers to handle entry and utilization limits.
Why APIs Are Central to Quant Workflows
Monetary information APIs rework information entry right into a programmable part of the analysis pipeline. As an alternative of guide preparation, information retrieval turns into built-in immediately into code, enabling constant inputs, sooner iteration, and scalable workflows.
This makes APIs a core a part of trendy quantitative analysis environments.
Forms of Monetary Knowledge Utilized in Algorithmic Buying and selling
As soon as information could be accessed programmatically, the subsequent step is knowing what sorts of datasets are generally utilized in quantitative analysis. These datasets type the enter layer of most analysis pipelines and are usually retrieved by means of monetary information APIs.
| Sort of Knowledge | Examples |
|---|---|
| Market Knowledge | Historic value information (open, excessive, low, shut, quantity), intraday value sequence, index and ETF costs |
| Basic Knowledge | Earnings statements (income, internet earnings), stability sheets (belongings, liabilities), money stream statements, and monetary ratios |
| Occasion & Macro Knowledge | Earnings calendars, analyst estimates and revisions, financial indicators (inflation, rates of interest, GDP) |
These datasets type the enter layer of most quantitative analysis workflows and are usually accessed by means of monetary information APIs.
Constructing a Quant Analysis Pipeline Utilizing a Monetary Knowledge API
To grasp how monetary information APIs help real-world workflows, let’s stroll by means of a simplified analysis situation. The purpose is to not construct a buying and selling technique, however to exhibit how information flows by means of a structured pipeline utilizing dependable and repeatable information sources.
Situation
A researcher desires to judge whether or not enhancing fundamentals can function a constant cross-sectional sign throughout a big universe of equities. This requires combining a number of datasets and analysing how monetary efficiency tendencies relate to noticed value behaviour throughout completely different firms.
Workflows like this are generally taught in structured quantitative finance packages, and replicate how structured analysis pipelines are in-built each tutorial {and professional} quant environments.
APIs Utilized in This Workflow
Earlier than constructing the pipeline, we outline the datasets and APIs required.
1. Historic Value Knowledge: Retrieve end-of-day value information for time-series evaluation.
2. Earnings Assertion Progress Knowledge: Retrieve development metrics equivalent to income development and earnings development.
Easy methods to Get Your API Key
To entry most monetary information APIs, customers usually register for an API key, which is included in requests for authentication and utilization monitoring. For instance, you’ll be able to register at Monetary Modeling Prep.
After registration, your API key can be obtainable in your dashboard. Exchange “YOUR_API_KEY” within the code examples under along with your private key to authenticate requests.
Step 1: Knowledge Ingestion
Step one within the pipeline is retrieving structured datasets utilizing monetary information APIs. As an alternative of manually accumulating information, we fetch each market information and elementary information programmatically.
Fetching Historic Value Knowledge
We start by retrieving end-of-day value information, which can be used to analyse value behaviour over time.
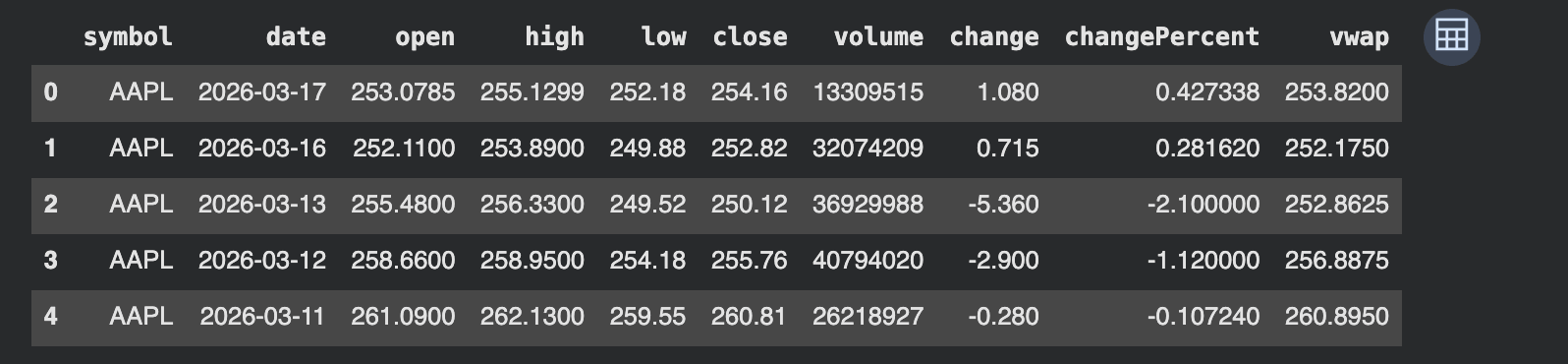
The output confirms that the API returned structured end-of-day value information for Apple in a clear tabular format. Every row represents one buying and selling day, whereas the columns seize key market fields equivalent to open, excessive, low, shut, quantity, day by day value change, proportion change, and VWAP.
This issues as a result of the dataset is straight away usable inside a analysis atmosphere with out further guide formatting. A researcher can kind by date, filter particular intervals, calculate rolling statistics, align costs with elementary occasions, or merge this desk with different datasets equivalent to earnings assertion development or analyst estimates.
Fetching Basic Progress Knowledge
To help the analysis goal, we additionally retrieve elementary development metrics. These datasets assist seize how an organization’s monetary efficiency is evolving over time.
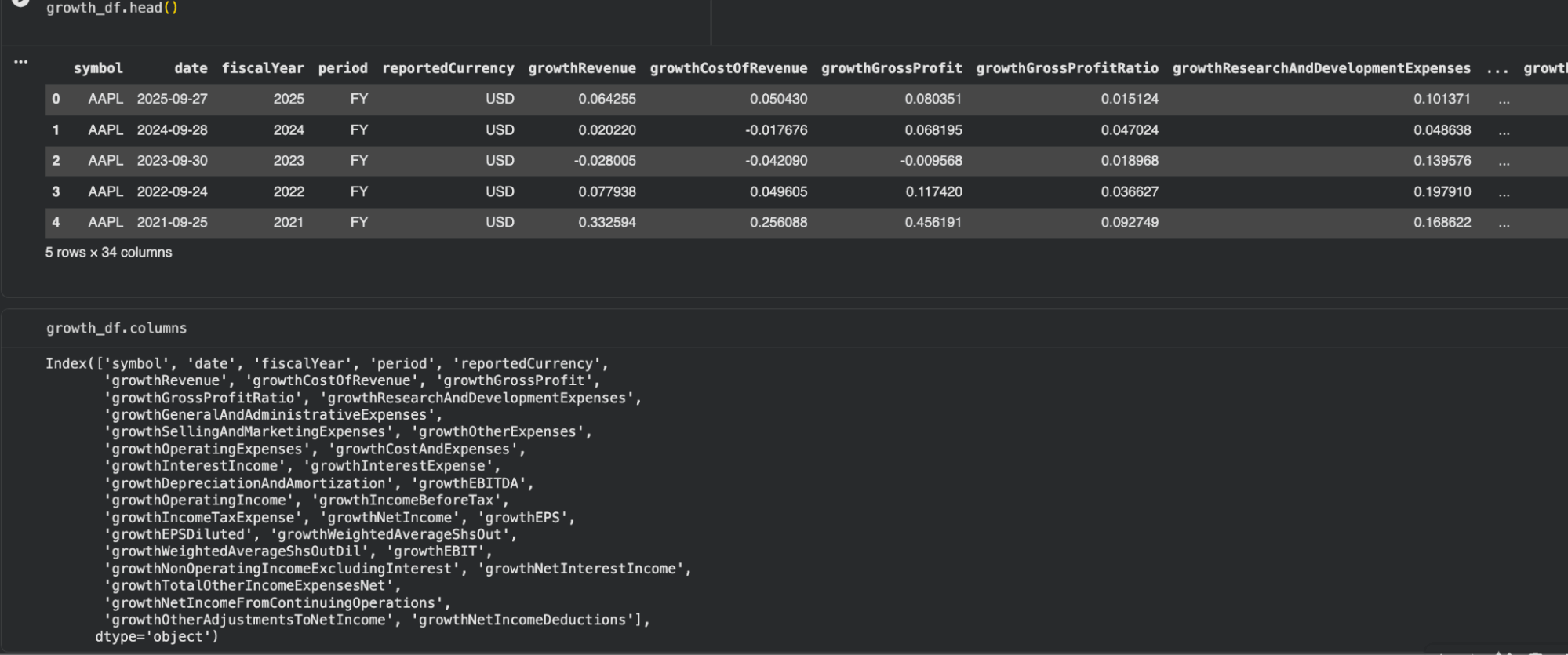
Interpretation
The output exhibits that the API returned structured elementary development information for Apple throughout a number of fiscal years. Every row represents a reporting interval, whereas the columns seize development metrics throughout completely different parts of the earnings assertion.
Key observations from the dataset:
- growthRevenue displays how the corporate’s income has modified 12 months over 12 months
- growthGrossProfit and growthGrossProfitRatio present perception into profitability tendencies
- growthNetIncome and growthEPS point out how earnings are evolving
- Further fields, equivalent to working bills, R&D, and EBITDA development, present a deeper breakdown of enterprise efficiency
The dataset is already preprocessed, which means development values are immediately obtainable with out requiring guide calculations. This reduces preprocessing effort and ensures consistency throughout firms.
One other essential side is the time granularity. Not like value information (day by day), this dataset is reported at a monetary interval degree (annual on this case). This distinction turns into essential when combining datasets later within the pipeline.
Total, this dataset captures how the corporate’s fundamentals are evolving over time, which enhances the price-based dataset retrieved earlier.
Step 2: Characteristic Engineering
As soon as each market information and elementary information can be found, the subsequent step is to rework them into structured variables that may help evaluation.
Engineering Value-Primarily based Options
We start by deriving options from the worth dataset.
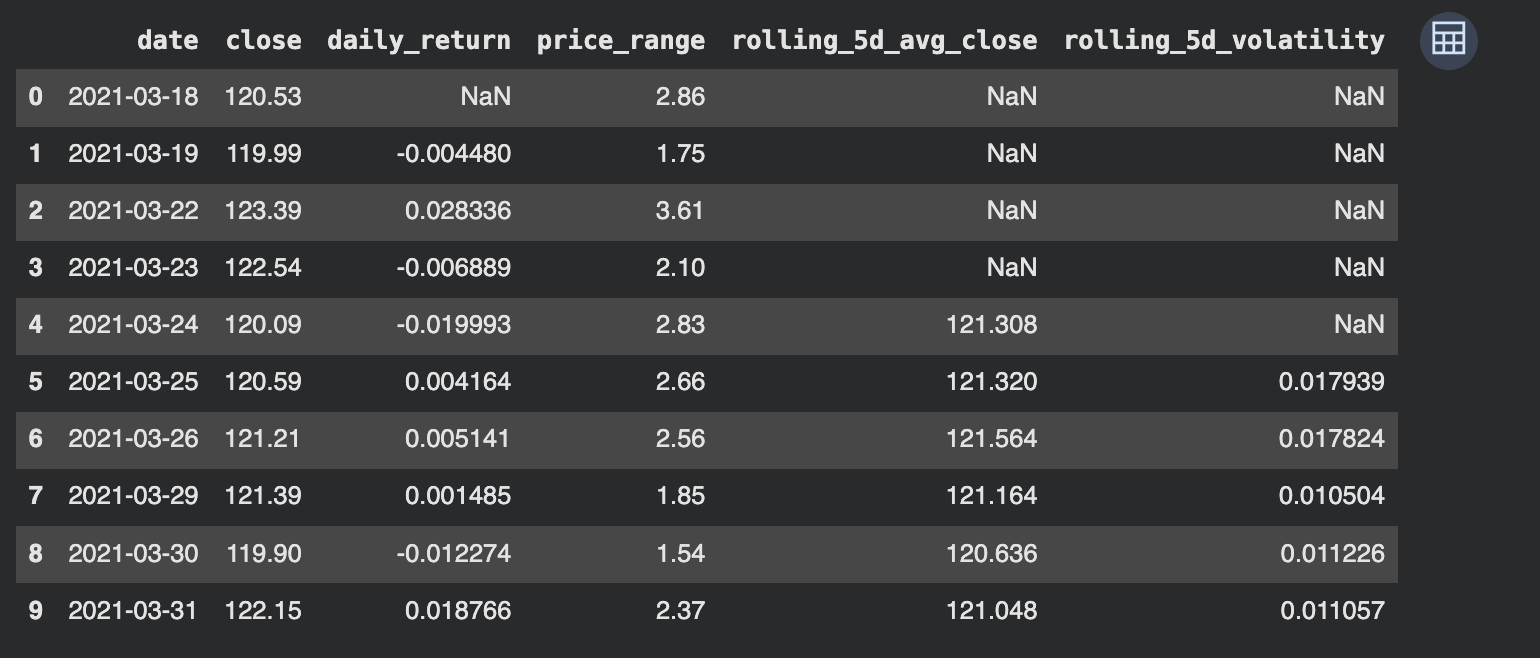
The engineered dataset exhibits how uncooked value information has been reworked into structured options that help evaluation.
Every function captures a special side of market behaviour:
- daily_return measures short-term value motion
- price_range displays intraday volatility
- rolling_5d_avg_close captures short-term pattern course
- rolling_5d_volatility measures the soundness of returns over time
Preliminary NaN values are anticipated, as rolling calculations require a minimal variety of observations.
This step highlights how uncooked market information is transformed into options that may be in contrast throughout time and mixed with different datasets, equivalent to monetary statements.
Working with Basic Progress Options
Not like value information, the elemental dataset already supplies engineered development variables. These can be utilized immediately with out further transformation.
Examples of obtainable options embody:
- Income development (growthRevenue)
- Gross revenue development (growthGrossProfit)
- Web earnings development (growthNetIncome)
- Earnings per share development (growthEPS)
These variables describe how the corporate’s monetary efficiency is altering over time, which is central to many analysis workflows.
Aligning Value and Basic Knowledge
An essential step in function engineering is aligning datasets that function at completely different frequencies. Incorrect alignment between reporting intervals and value information is without doubt one of the commonest sources of bias in quantitative analysis, notably when elementary information is forward-filled improperly.
- Value information → day by day
- Basic information → annual or quarterly
To mix them, researchers usually map elementary values to corresponding value intervals. This may be performed utilizing strategies equivalent to:
- Ahead filling monetary information throughout day by day rows (with warning to keep away from look-ahead bias)
- Merging datasets primarily based on reporting dates
- Creating time-aligned snapshots
Under is a simplified instance illustrating how these datasets could be aligned:
This alignment ensures that each market behaviour and enterprise efficiency could be analysed collectively inside a unified dataset.
Key Final result of Characteristic Engineering
At this stage, the dataset comprises:
- Value-based options describing market motion
- Basic options describing enterprise efficiency
This mixture permits extra significant evaluation, the place value behaviour could be evaluated alongside adjustments in firm fundamentals.
Step 3: Speculation Testing
With each price-based options and elementary development information obtainable, the researcher can now start evaluating relationships inside the information in a structured method.
At this stage, the purpose is to not construct a buying and selling technique, however to check whether or not observable patterns exist between market behaviour and underlying enterprise efficiency.
Defining the Analysis Query
A easy and significant speculation may very well be:
Do intervals of steady value behaviour systematically align with enhancing firm fundamentals?
This connects two key dimensions:
- Market behaviour → captured by means of value volatility
- Enterprise efficiency → captured by means of development metrics
Structuring the Evaluation
To judge this speculation, the researcher can:
- Establish intervals the place short-term volatility is comparatively low
(utilizing rolling_5d_volatility) - Observe corresponding elementary development tendencies, equivalent to:
- Income development (growthRevenue)
- Web earnings development (growthNetIncome)
- Examine whether or not:
- Secure value intervals coincide with enhancing fundamentals
- Or whether or not no constant relationship exists
Instance Workflow
A simplified analytical method might contain:

The filtered dataset highlights intervals the place short-term volatility is comparatively low, primarily based on the decrease quantile of the rolling 5-day volatility.
From the pattern:
- The rolling_5d_volatility values (~0.008–0.009) point out comparatively steady value actions
- Throughout these intervals, daily_return values are reasonable and managed, with out excessive spikes
- The price_range stays inside a slender band, suggesting restricted intraday fluctuation
- The rolling_5d_avg_close strikes regularly, indicating clean short-term tendencies slightly than abrupt value adjustments
For instance:
- On 2021-04-07 to 2021-04-09, costs present regular upward motion with low volatility
- On 2021-04-22 and 2021-04-29, even when returns flip barely adverse, volatility stays contained, suggesting managed corrections slightly than sharp declines
This output demonstrates that:
- Low volatility intervals will not be essentially flat markets
- They will symbolize steady pattern phases, though this relationship might fluctuate throughout belongings and market circumstances.
- These phases are structurally completely different from high-volatility intervals, which have a tendency to incorporate abrupt actions and uncertainty
This statement highlights how combining price-based options with elementary development information permits a extra structured analysis of market behaviour, shifting the evaluation from descriptive patterns to testable relationships.
Step 4: Scaling the Analysis
In {most professional} environments, analysis pipelines are designed to function throughout a whole lot or hundreds of securities, making scalability a core requirement slightly than an optimisation.
As soon as the workflow is validated for a single firm, the identical pipeline could be prolonged throughout a bigger universe of securities.
As a result of each information ingestion and have engineering are applied in code, the method could be repeated with minimal adjustments.
In follow, scaling might contain:
- Working the pipeline throughout a listing of symbols as a substitute of a single inventory
- Combining outcomes right into a unified dataset for cross-sectional evaluation
- Refreshing the info at common intervals utilizing automated scripts
- Reusing the identical function definitions throughout a number of analysis questions
For instance, the identical function engineering logic utilized to Apple could be utilized to a whole lot of shares utilizing a easy loop or batch course of.
That is the place monetary information APIs play a essential function. They permit researchers to maneuver from remoted examples to scalable analysis programs, the place information retrieval, transformation, and evaluation could be executed constantly throughout giant datasets.
Why Knowledge High quality Issues in Systematic Buying and selling
At this stage, the analysis pipeline is structured and repeatable. Nevertheless, the reliability of any evaluation nonetheless depends upon the standard of the underlying information. Even well-designed workflows can produce deceptive outcomes if the enter information is incomplete, inconsistent, or incorrectly adjusted.
Knowledge high quality isn’t just a technical concern. It immediately impacts how precisely a researcher can consider patterns, evaluate firms, and validate hypotheses.
Frequent Knowledge Points in Quantitative Analysis
Monetary datasets usually include points that aren’t instantly seen however can considerably have an effect on evaluation. Frequent challenges embody survivorship bias, lookahead bias from incorrect timestamps, lacking historic information, and improper dealing with of company actions equivalent to splits or dividends.
These points turn into extra pronounced when scaling evaluation throughout a number of securities or time intervals.
Influence on Analysis Outcomes
Knowledge high quality immediately impacts each stage of the pipeline, from function engineering to speculation testing. Inconsistent or incomplete information can result in distorted indicators, unreliable comparisons, and deceptive conclusions.
Function of Monetary Knowledge APIs
Dependable monetary information APIs assist scale back many of those challenges by offering standardised and structured datasets. With constant schemas, preprocessed metrics, and common updates, APIs make it simpler to combine a number of datasets right into a unified analysis pipeline.
Why Knowledge High quality Is Foundational
Knowledge high quality immediately influences the credibility of quantitative analysis.
If the enter information is dependable:
- Outcomes are simpler to validate
- Experiments are reproducible
- Insights are extra constant
If the enter information is flawed:
- Patterns might seem the place none exist
- Comparisons throughout securities could also be inaccurate
- Analysis conclusions turn into troublesome to belief
Because of this information high quality is taken into account a foundational layer in systematic buying and selling. Earlier than evaluating any speculation, researchers should make sure that the info getting used is correct, constant, and full.
Key Takeaways
- For practitioners, the important thing takeaway is that dependable information infrastructure is a prerequisite for significant backtesting, sturdy function engineering, and scalable technique improvement.
- Platforms like Monetary information APIs allow constant and programmatic entry to datasets equivalent to costs, monetary statements, and analyst estimates.
- Integrating APIs into Python workflows improves automation, reduces guide effort, and ensures reproducibility.
- A well-designed information layer permits analysis pipelines to scale throughout a number of securities and time intervals.
- Knowledge consistency and high quality immediately influence the reliability of options, indicators, and analysis conclusions.
- In follow, the reliability of a quantitative workflow relies upon extra on the power of its information pipeline than on the complexity of its fashions.
Concerning the Contributor
Monetary Modeling Prep (FMP) supplies structured monetary information APIs used throughout quantitative analysis, funding evaluation, and developer workflows. Its platform is designed to help scalable entry to market information, monetary statements, estimates, and different datasets generally utilized in systematic analysis environments.
Disclaimer: All information and knowledge supplied on this article are for informational functions solely. QuantInsti® makes no representations as to accuracy, completeness, currentness, suitability, or validity of any data on this article and won’t be answerable for any errors, omissions, or delays on this data or any losses, accidents, or damages arising from its show or use. All data is supplied on an as-is foundation.



